Acoustic-to-articulatory inversion using an HMM-based speech production model
HMM-based Speech Production Model
Acoustic-to-articulatory inverse mapping is characterized by one-to-many mapping.
This problem focuses on dynamical constraints in order to uniquely determine
articulatory movements from speech acoustics.
One of the stochastic dynamical models is hidden Markov model (HMM), which represents dynamical behavior
as well as the trajectory smoothness.
Therefore, we proposed an acoustic-to-articulatory inversion method using an HMM-based speech production model.
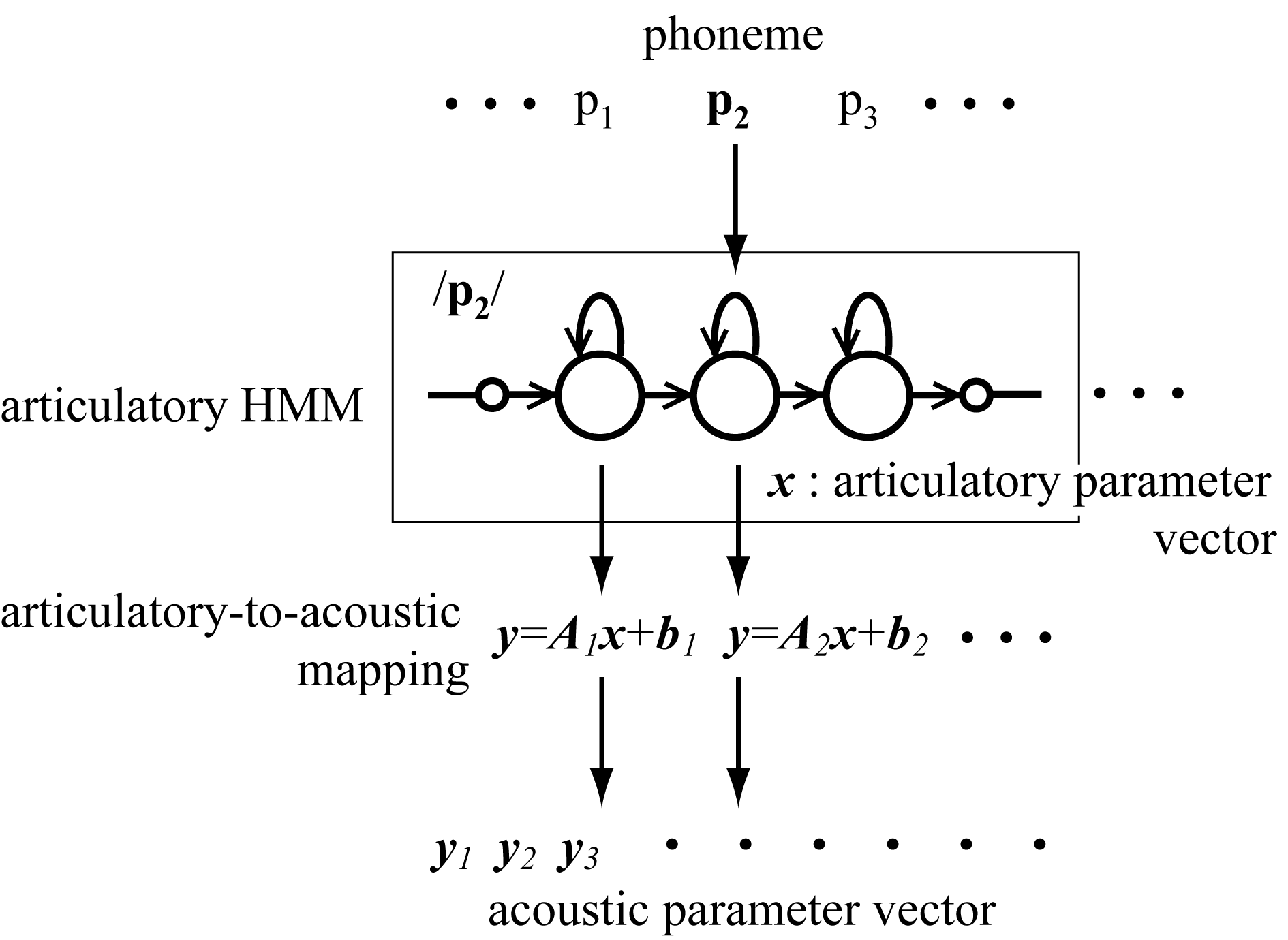
The HMM-based speech production model consists of HMMs that represent articulatory parameters,
called the articulatory HMM, and an articulatory-to-acoustic mapping.
The articulatory HMM has a sequence of states for each phoneme and generates an articulatory parameter vector
in a probabilistic form for a given phoneme sequence.
For a given articulatory parameter vector, the articulatory-to-acoustic mapping generates the acoustic
parameter vector in a probabilistic form for each HMM state.
There is a non-linear relationship between the articulatory and acoustic parameters.
Therefore, the linear mapping was assigned to each HMM state to approximate the non-linear relationship
between the articulatory and acoustic parameters in a piecewise linear form.
The model was statistically constructed by using actual articulatory-acoustic data.
Articulatory movements and speech acoustics data were obtained from simultaneous observations using the electro-magnetic
articulographic (EMA) system and acoustic recordings of continuous speech utterances.
The articulatory parameters were represented by the vertical and horizontal positions of eight coils, which were
placed on the lower jaw, the upper and lower lips, the tongue (four positions), and the velum.
The cepstrum coefficients were obtained as acoustic parameters.
Estimation of articulatory parameters from speech spectrum
For a given acoustic parameter vector sequence, an articulatory parameter vector sequence is determined
by using an HMM-based speech production model.
First, we conduct a spectral analysis of every frame.
For a given spectrum sequence, the optimal HMM state sequence is determined by using the Viterbi algorithm.
Then, for a given speech spectrum sequence and the optimal HMM state sequence, articulatory parameter vector
are determined by finding the maximum a-posteriori estimate.
Demonstration [a01mini.mov (about 1.5MB)]
The video shows the articulatory movements for a mid-sagittal section with speech.
Red points indicate the lower jaw, the lower and upper lips, the tongue (four points), and the velar, respectively.
First, left figure shows the measured articulatory movements with original speech.
Secondly, right figure shows the estimated articulatory movements from the speech spectrum with re-synthesized speech.
Re-synthesized speech is obtained from the estimated articulatory movements, and periodic pulse and white noise excitation.
Finally, I'll show you the slow motion.
This video says a Japanese sentence /go-go-wa-ta-ma-Q-ta-sho-ru-i-ni-me-wo-to-si-ma-su/.
The average RMS error between the measured and estimated articulatory parameters was 1.50 mm and
the average spectral distance between the vocal-tract spectrum and re-synthesized speech spectrum
was 3.40 dB.
Left: Measured. Right: Estimated.
Reference
Hiroya, S. and Honda, M., ``Estimation of Articulatory Movements from Speech Acoustics Using an HMM-Based Speech Production Model,''
IEEE Transactions on Speech and Audio Processing, vol. 12, no. 2, pp. 175-185, 2004.
back