谷山秀昭 下川辺隆史* 青木尊之* 納富雅也
量子光物性研究部 *東京工業大学
マックスウェル方程式の数値的な解法であるFinite-Difference Time-Domain (FDTD)法は、光学微細構造における光の解析から素子構造の設計において重要なツールとしての位置を占めている。しかし、この手法による計算プログラムは、大容量のメモリと長時間の計算を必要とするため適用範囲は制限されてきた。今回我々は、スーパーコンピュータに搭載されるなど近年急速に注目を集めているGeneral-Purpose Graphics Processing Unit (GPGPU)をアクセラレータとして用いることにより、FDTD計算の高速化を行うことを検討した。
FDTD法では、電磁場の時間積分計算において大量のメモリアクセスが発生する。通常のCPUによる計算の場合、そのメモリアクセスの遅さが高速化の妨げとなっている。それに対し、GPUはCPUと比較してメモリに高速にアクセスできる。しかしGPUを利用する場合でも、一部の計算をCPUで行うとなるとGPUからCPUに大量のデータを転送しなければならなくなり、計算時間よりも転送時間の方が長くなってしまうことがある。このデータ転送の回数を減らし、可能な限りGPU内で計算を行うようにコーディングすることで、GPU本来の高いメモリバンド幅と複数プロセッサによる高い演算性能を引き出した。
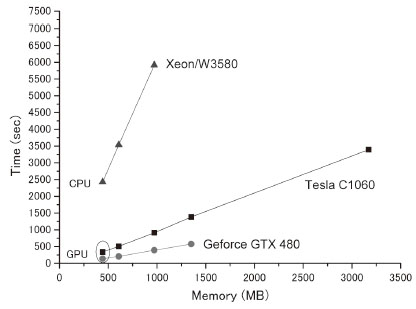
図1(a)に示した3点欠陥フォトニック結晶スラブ共振器に対して、3次元FDTD法を用いてその共振モードを計算した[図1(b)]。その際、CPUのみを使用した場合とGPUを利用した場合で計算時間を比較した結果を図2に示す。使用したCPUはIntel Xeon/W3580 3.33 GHz、GPUはNVIDIA Tesla C1060とGeForce GTX 480である。なおプログラミング環境としてCUDAを用い、計算は全て倍精度で行なった[1]。図に示されたように、CPUだけの計算と比較して、GPUを利用することで最大で18倍程度の高速化が達成できた。またTeslaに対して、GTX 480が2.5倍程度早いのは、メモリバンド幅とL1キャッシュの違いによると推測される。
[1] H. Taniyama et al., PIERS 2011, 1A9-K-14, March (2011).
 |
 |
|||||
|
|